Publications
A collection of my research work.
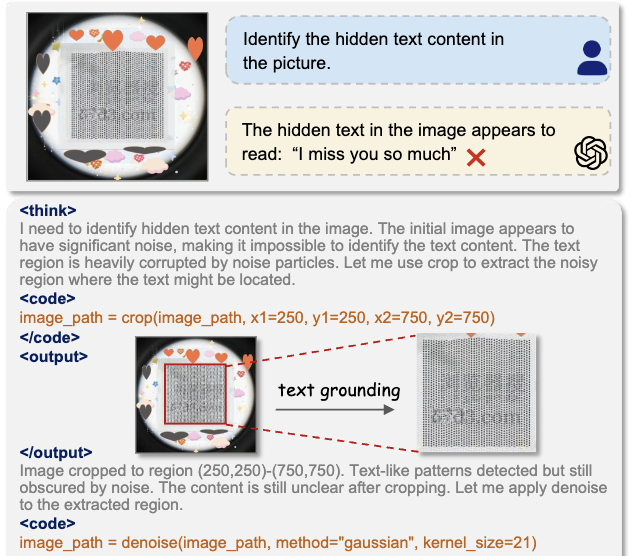
VACoT: Rethinking Visual Data Augmentation with VLMs
Zhengzhuo Xu, Chong Sun, SiNan Du, Chen Li, Jing LYU, Chun Yuan
Arxiv preprint 2025
A research on Visual Augmentation Chain-of-Thought, a framework that dynamically applies visual augmentations during VLM inference to enhance robustness on challenging/out-of-distribution inputs. It integrates diverse general augmentations (beyond local cropping) with efficient agentic reinforcement learning & conditional rewards, achieving superior performance on 13 perception benchmarks and introducing AdvOCR to verify post-hoc augmentation benefits.
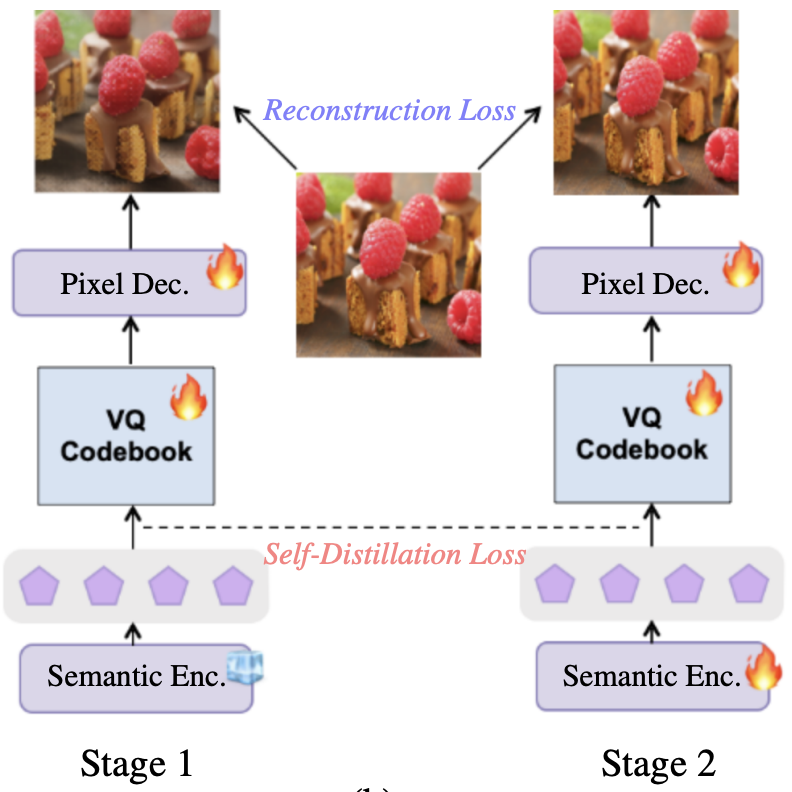
VQRAE: Representation Quantization Autoencoders for Multimodal Understanding, Generation and Reconstruction
Sinan Du, Jiahao Guo, Bo Li, Shuhao Cui, Zhengzhuo Xu, Yifu Luo, Yongxian Wei, Kun Gai, Xinggang Wang, Kai Wu, Chun Yuan
Arxiv preprint 2025
A research on VQRAE, a Vector Quantization-based Representation AutoEncoder that unifies multimodal understanding, generation and reconstruction in a single tokenizer: it produces continuous semantic features for image understanding and discrete tokens for visual generation via a two-stage training strategy (high-dimensional VQ codebook learning + encoder self-distillation), achieving high codebook utilization and competitive performance across visual tasks.
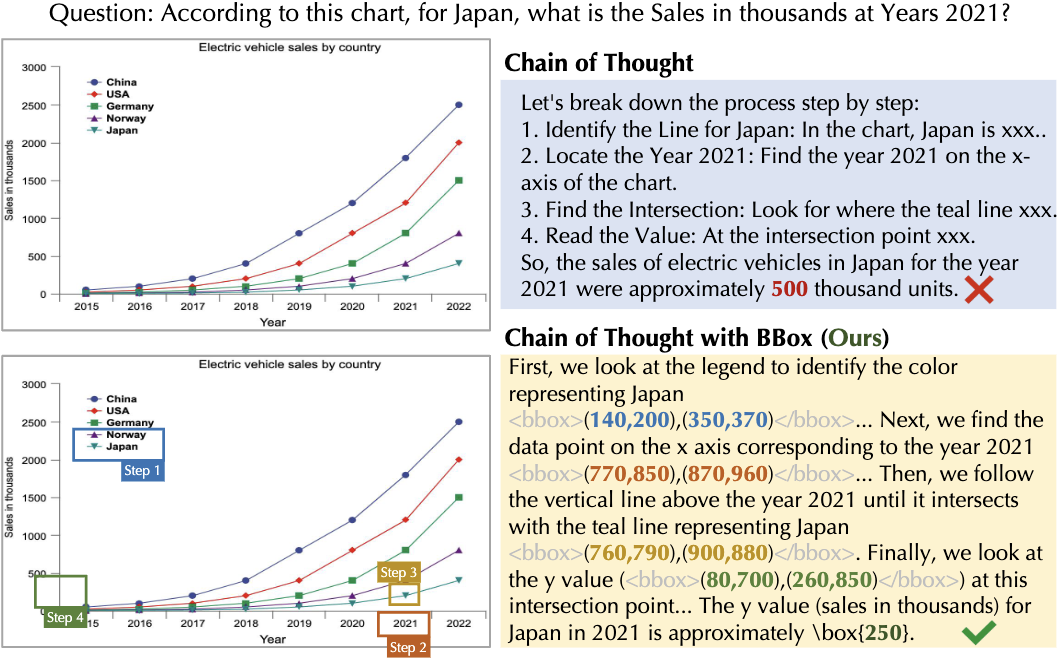
ChartPoint: Guiding MLLMs with Grounding Reflection for Chart Reasoning
Zhengzhuo Xu, Sinan Du, Yiyan Qi, Siwen Lu, Chengjin Xu, Chun Yuan, Jian Guo
IEEE/CVF International Conference on Computer Vision, ICCV 2025
A research on PointCoT, a framework integrating reflective interaction into chain-of-thought reasoning, designed to strengthen multimodal large language models' chart comprehension by linking textual reasoning with visual grounding, addressing numerical hallucinations and weak element grounding issues.
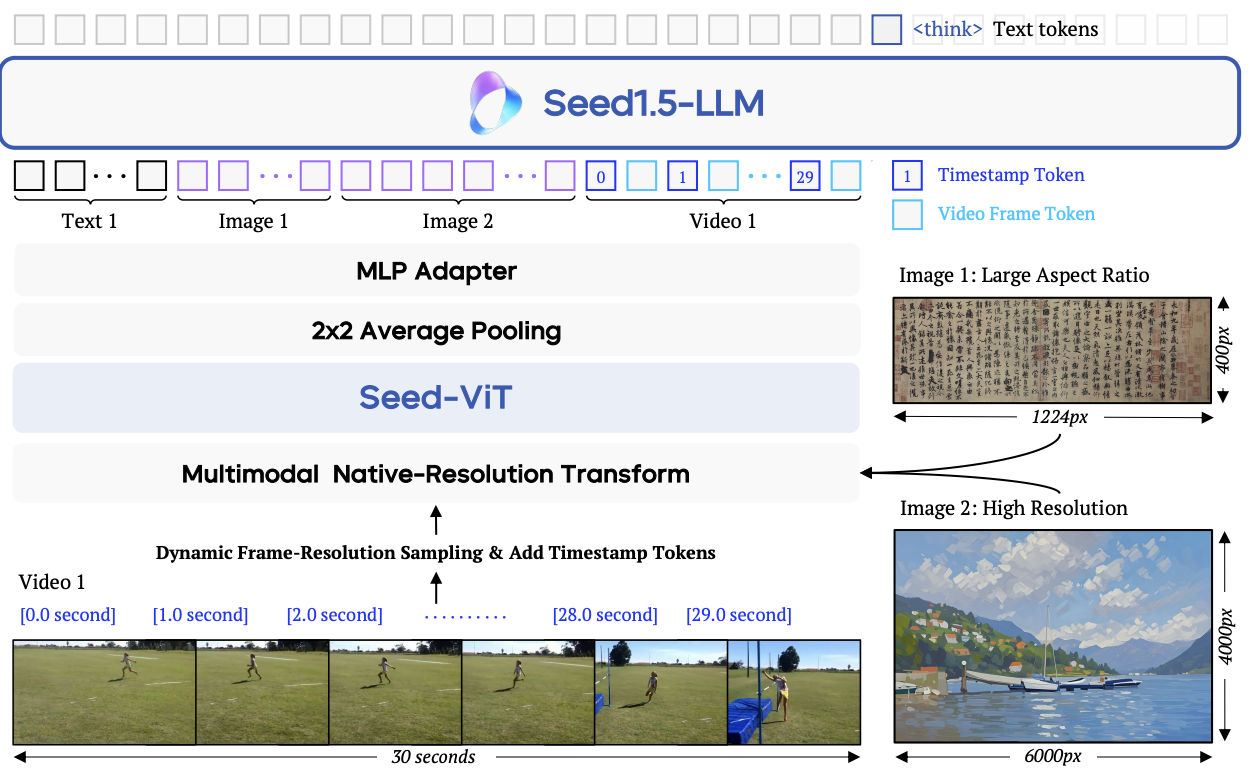
Seed1.5-VL Technical Report
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, Zhengzhuo Xu, others
Arxiv preprint 2025
A technical report on Seed1.5-VL, a multimodal model focusing on visual-language tasks, detailing the model architecture, training strategies, and performance evaluations across diverse multimodal benchmarks.

ChartMoE: Mixture of Expert Connector for Advanced Chart Understanding
Zhengzhuo Xu, Bowen Qu, Yiyan Qi, Sinan Du, Chengjin Xu, Chun Yuan, Jian Guo
International Conference on Learning Representations, ICLR oral 2025
A research on ChartMoE, a Mixture of Expert Connector framework designed to enhance advanced chart understanding capabilities, leveraging expert specialization to address complex visual and semantic reasoning challenges in chart data analysis.

Boosting Long-Tailed Recognition With Label Descriptor and Beyond
Zhengzhuo Xu, Ruikang Liu, Zenghao Chai, Yiyan Qi, Lei Li, Haiqin Yang, Chun Yuan
IEEE Trans. Multim. 2025
A study focusing on optimizing long-tailed recognition tasks, introducing label descriptor - based technologies and other auxiliary means to alleviate the impact of data class imbalance on model training, which is of great significance for promoting the practical application of recognition models in real - world scenarios with unbalanced data distribution.
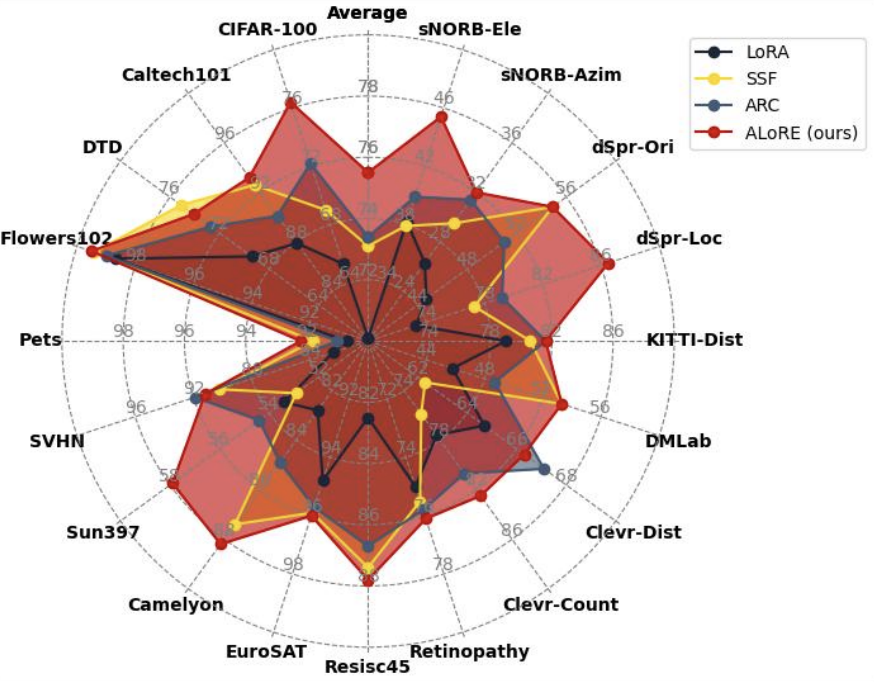
ALoRE: Efficient Visual Adaptation via Aggregating Low Rank Experts
Sinan Du, Guosheng Zhang, Keyao Wang, Yuanrui Wang, Haixiao Yue, Gang Zhang, Errui Ding, Jingdong Wang, Zhengzhuo Xu, Chun Yuan
Arxiv preprint 2024
A research on ALoRE framework for efficient visual adaptation, proposing to aggregate low rank experts to reduce the computational overhead of visual model adaptation while maintaining performance in computer vision tasks.

IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact
Ruikang Liu, Haoli Bai, Haokun Lin, Yuening Li, Han Gao, Zhengzhuo Xu, Lu Hou, Jun Yao, Chun Yuan
Findings of the Association for Computational Linguistics, ACL 2024
A research on IntactKV framework for large language model quantization, proposing to keep pivot tokens intact to reduce quantization errors and enhance the precision of quantized LLMs in natural language processing tasks.
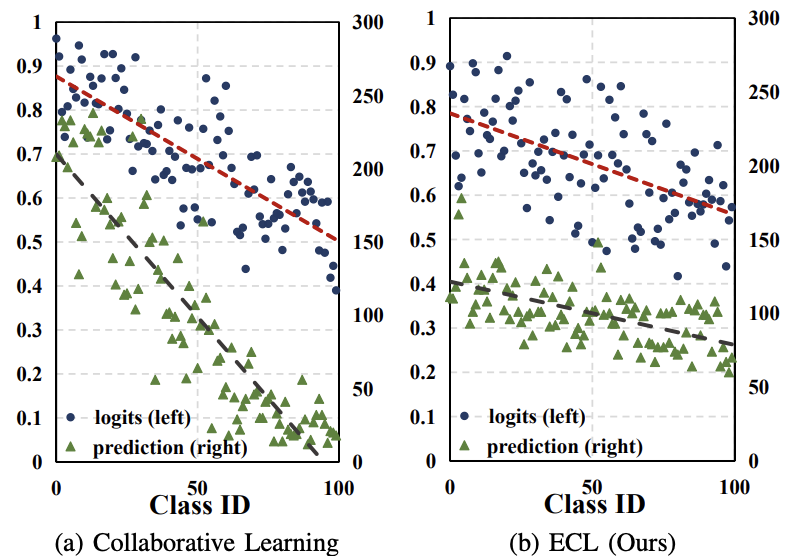
Towards Effective Collaborative Learning in Long-Tailed Recognition
Zhengzhuo Xu, Zenghao Chai, Chengyin Xu, Chun Yuan, Haiqin Yang
IEEE Trans. Multim. 2024
A research on effective collaborative learning strategies for long-tailed recognition tasks, exploring collaborative mechanisms to address the class imbalance problem in multimedia and computer vision scenarios.
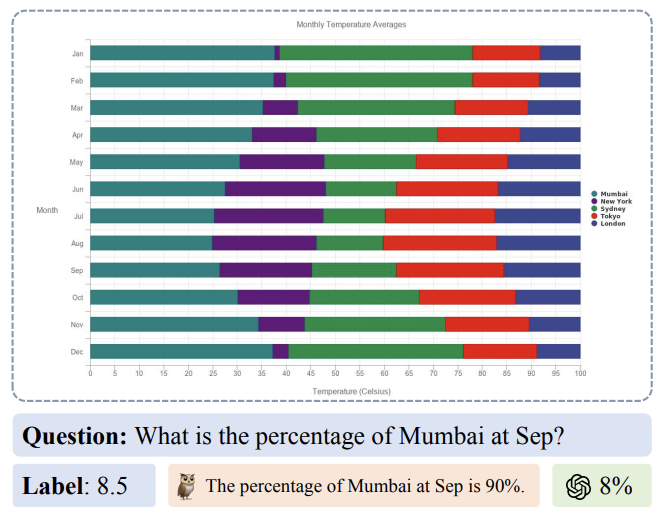
ChartBench: A Benchmark for Complex Visual Reasoning in Charts
Zhengzhuo Xu, Sinan Du, Yiyan Qi, Chengjin Xu, Chun Yuan, Jian Guo
Arxiv preprint 2023
A research on ChartBench, a novel benchmark designed to evaluate the complex visual reasoning capabilities of models on chart data, covering diverse chart types and reasoning tasks in visual analytics.
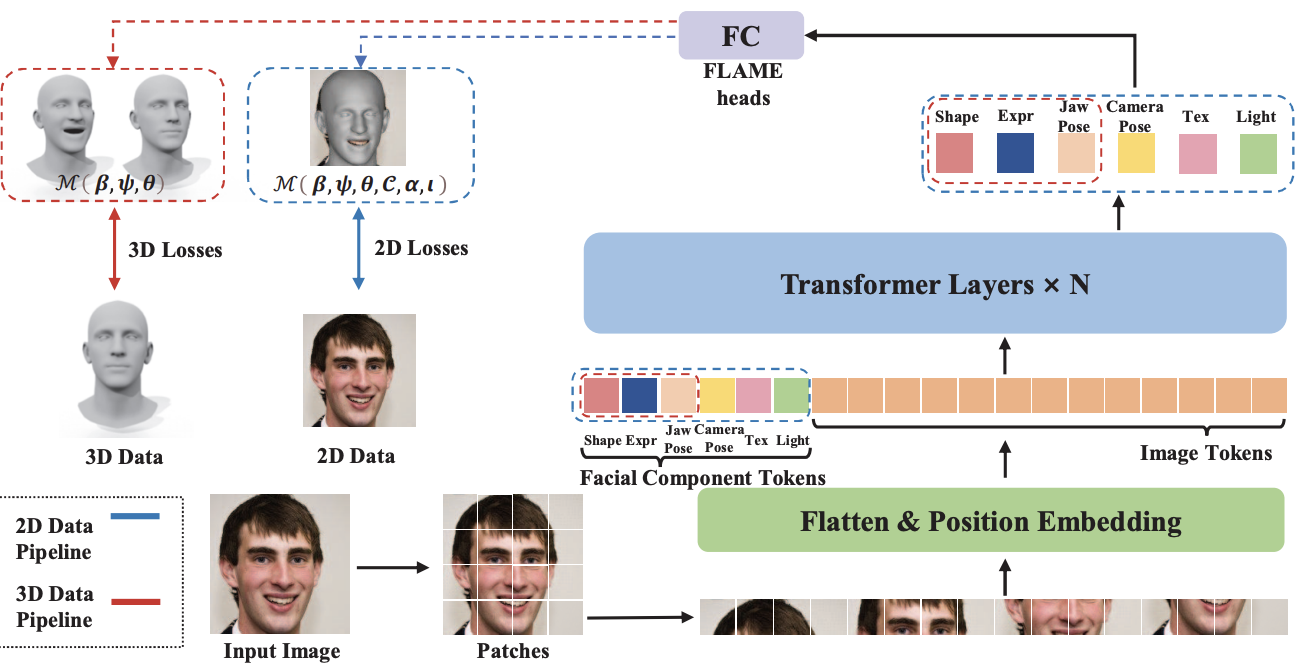
Accurate 3D Face Reconstruction with Facial Component Tokens
Tianke Zhang, Xuangeng Chu, Yunfei Liu, Lijian Lin, Zhendong Yang, Zhengzhuo Xu, Chengkun Cao, Fei Yu, Changyin Zhou, Chun Yuan, Yu Li
IEEE/CVF International Conference on Computer Vision, ICCV 2023
A research on accurate 3D face reconstruction leveraging facial component tokens, proposing a novel token-based approach to enhance the precision and detail of 3D facial structure reconstruction in computer vision tasks.

Learning Imbalanced Data with Vision Transformers
Zhengzhuo Xu, Ruikang Liu, Shuo Yang, Zenghao Chai, Chun Yuan
IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023
A research on learning imbalanced data with Vision Transformer models, proposing novel strategies to address the class imbalance challenge in computer vision tasks using ViT architectures.

Rethink Long-Tailed Recognition with Vision Transforms
Zhengzhuo Xu, Shuo Yang, Xingjun Wang, Chun Yuan
International Conference on Acoustics, Speech and Signal Processing ICASSP 2023
A research rethinking long-tailed recognition tasks with Vision Transformer models, exploring the advantages of ViT in addressing the class imbalance problem in long-tailed visual recognition scenarios.
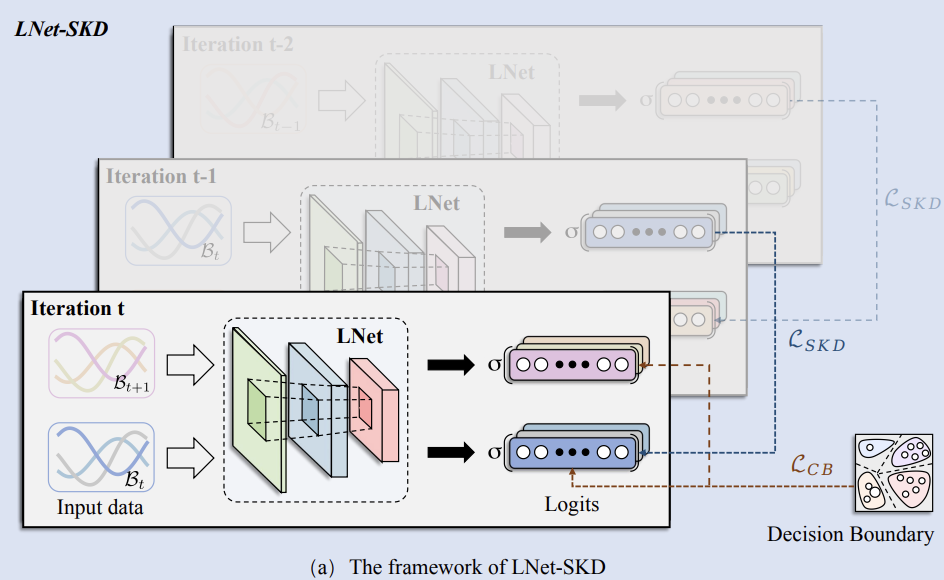
A Lightweight Approach for Network Intrusion Detection Based on Self-Knowledge Distillation
Shuo Yang, Xinran Zheng, Zhengzhuo Xu, Xingjun Wang
IEEE International Conference on Communications, ICC 2023
A research on a lightweight network intrusion detection approach based on self-knowledge distillation, designed to enhance the efficiency and accuracy of intrusion detection in communication networks.
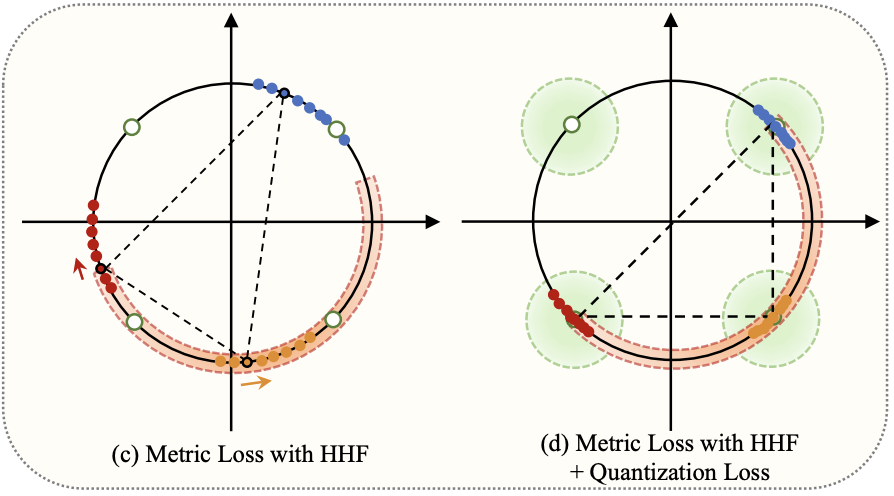
HHF: Hashing-Guided Hinge Function for Deep Hashing Retrieval
Chengyin Xu, Zenghao Chai, Zhengzhuo Xu, Hongjia Li, Qiruyi Zuo, Lingyu Yang, Chun Yuan
IEEE Trans. Multim. 2023
A research on the HHF (Hashing-Guided Hinge Function) framework for deep hashing retrieval, leveraging hashing guidance to optimize hinge functions and enhance the efficiency and accuracy of deep hashing-based retrieval tasks.

HyP^2 Loss: Beyond Hypersphere Metric Space for Multi-label Image Retrieval
Chengyin Xu, Zenghao Chai, Zhengzhuo Xu, Chun Yuan, Yanbo Fan, Jue Wang
ACM International Conference on Multimedia, ACM MM 2022
A research on the HyP(^mbox2) Loss function that breaks through the limitations of the hypersphere metric space, aiming to improve the performance of multi-label image retrieval tasks in multimedia processing.
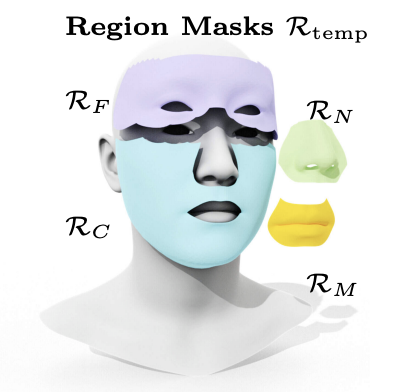
REALY: Rethinking the Evaluation of 3D Face Reconstruction
Zenghao Chai, Haoxian Zhang, Jing Ren, Di Kang, Zhengzhuo Xu, Xuefei Zhe, Chun Yuan, Linchao Bao
European Conference Computer Vision, ECCV 2022
A research on REALY framework that rethinks the evaluation metrics and methodologies for 3D face reconstruction, aiming to provide more accurate and comprehensive evaluation criteria for the field.

Semantic-Sparse Colorization Network for Deep Exemplar-Based Colorization
Yunpeng Bai, Chao Dong, Zenghao Chai, Andong Wang, Zhengzhuo Xu, Chun Yuan
European Conference Computer Vision, ECCV 2022
A research on the Semantic-Sparse Colorization Network, proposing a novel deep exemplar-based colorization approach that leverages semantic sparsity to enhance colorization accuracy and realism.
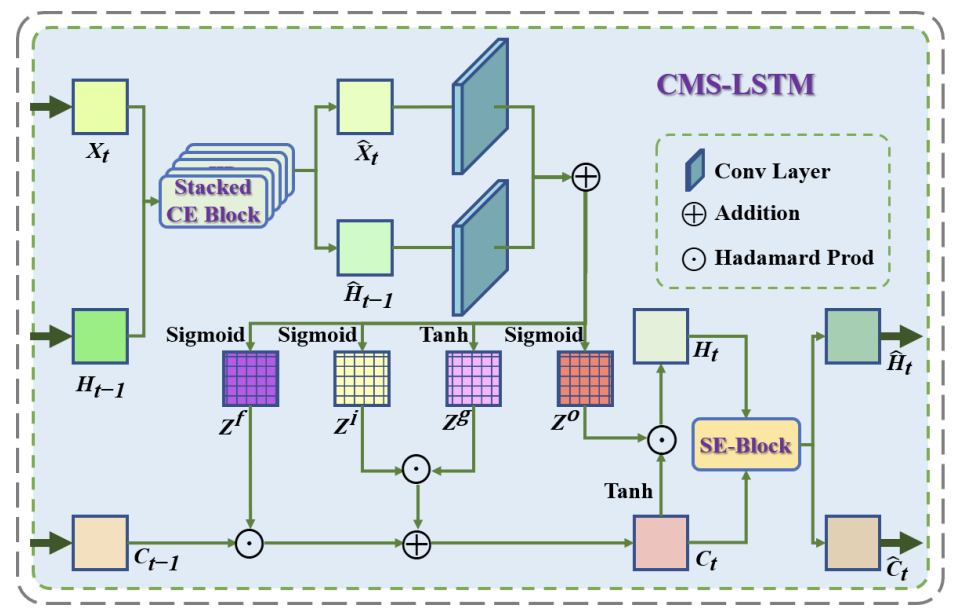
CMS-LSTM: Context Embedding and Multi-Scale Spatiotemporal Expression LSTM for Predictive Learning
Zenghao Chai, Zhengzhuo Xu, Yunpeng Bai, Zhihui Lin, Chun Yuan
IEEE International Conference on Multimedia and Expo, ICME 2022
A study on the CMS-LSTM framework integrating context embedding and multi-scale spatiotemporal expression, designed to boost predictive learning performance in multimedia spatiotemporal tasks.
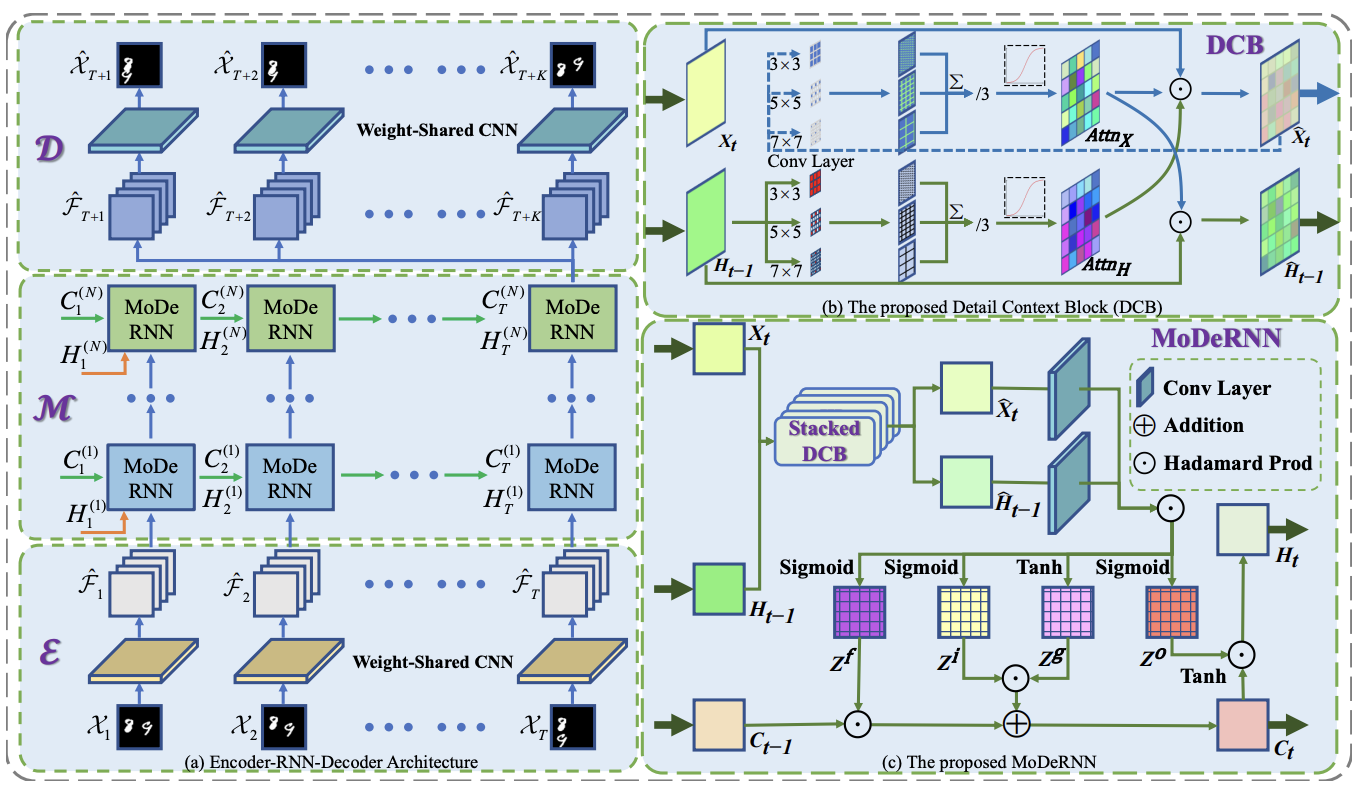
Modernn: Towards Fine-Grained Motion Details for Spatiotemporal Predictive Learning
Zenghao Chai, Zhengzhuo Xu, Chun Yuan
IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022
A research on Modernn framework for capturing fine-grained motion details, aiming to enhance spatiotemporal predictive learning performance in visual signal processing tasks.
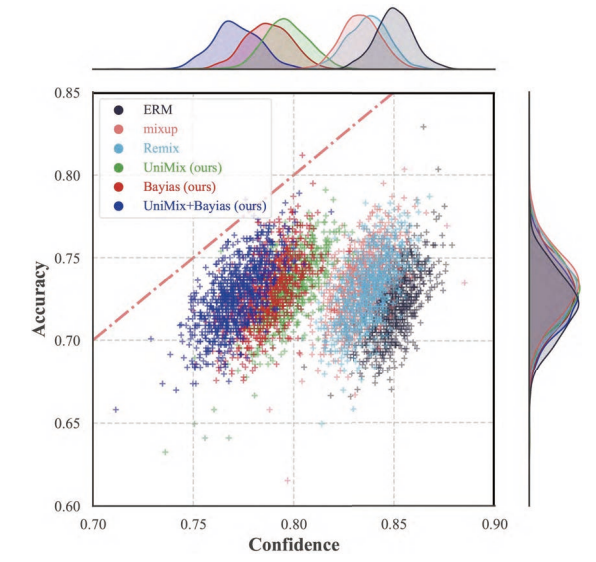
Towards Calibrated Model for Long-Tailed Visual Recognition from Prior Perspective
Zhengzhuo Xu, Zenghao Chai, Chun Yuan
Advances in Neural Information Processing Systems, NeurIPS 2021
A research on calibrated models for long-tailed visual recognition from a prior perspective, addressing the calibration and classification challenges in long-tailed visual data scenarios.
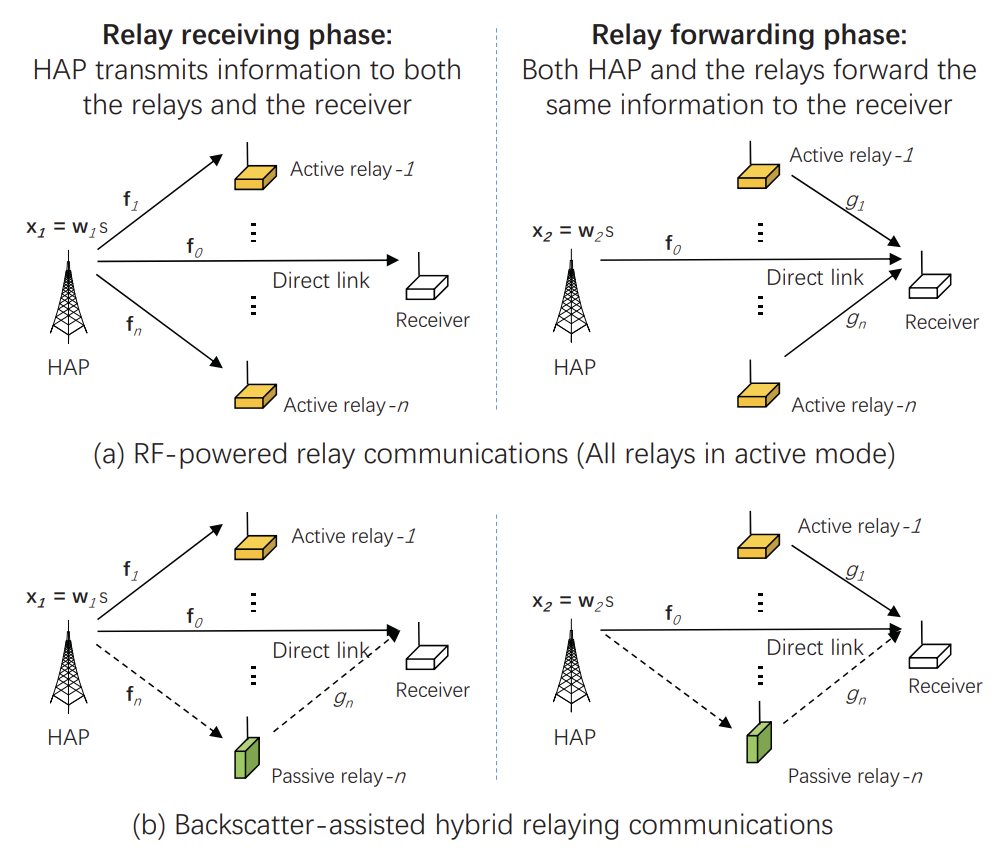
Backscatter-Assisted Hybrid Relaying Strategy for Wireless Powered IoT Communications
Yutong Xie, Zhengzhuo Xu, Shimin Gong, Jing Xu, Dinh Thai Hoang, Dusit Niyato
IEEE Global Communications Conference, GLOBECOM 2019
A study on backscatter-assisted hybrid relaying strategies for wireless powered IoT communications, exploring optimized relaying schemes to enhance the performance of IoT communication systems.
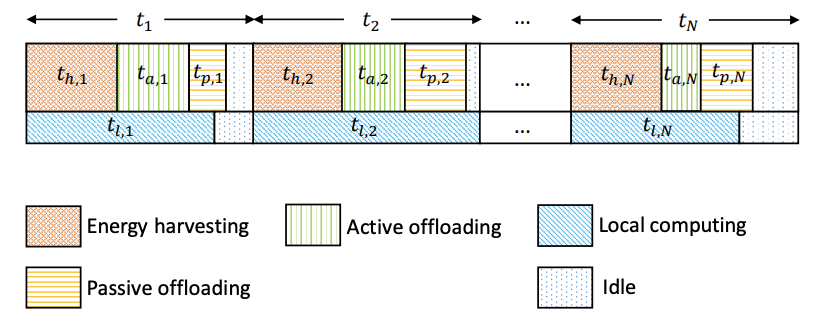
Backscatter-Assisted Computation Offloading for Energy Harvesting IoT Devices via Policy-based Deep Reinforcement Learning
Yutong Xie, Zhengzhuo Xu, Yuxing Zhong, Jing Xu, Shimin Gong, Yi Wang
IEEE/CIC International Conference on Communications Workshops 2019
A research on backscatter-assisted computation offloading for energy harvesting IoT devices, adopting policy-based deep reinforcement learning to optimize offloading decisions for energy-constrained IoT scenarios.
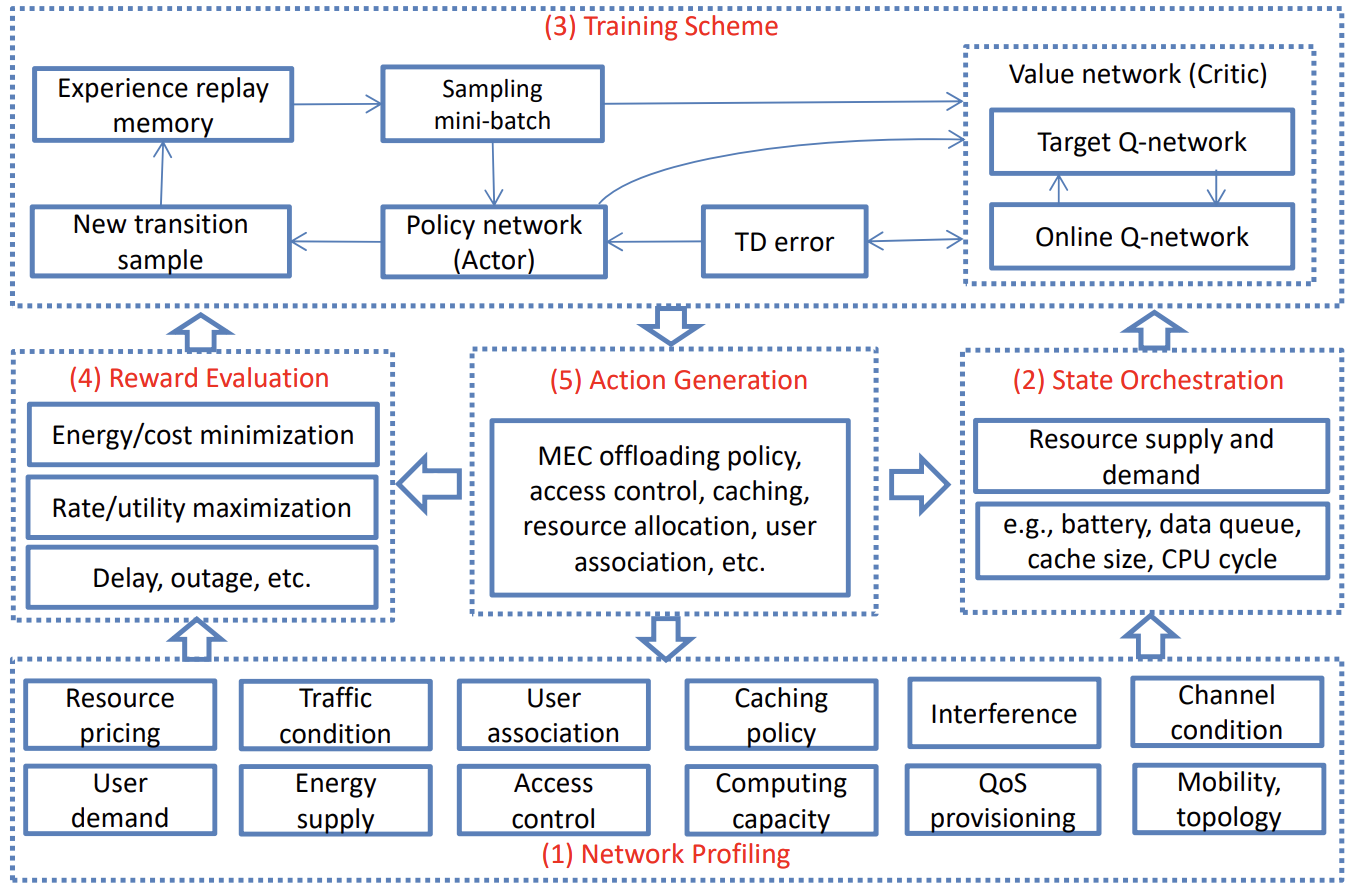
Backscatter-Aided Hybrid Data Offloading for Mobile Edge Computing via Deep Reinforcement Learning
Yutong Xie, Zhengzhuo Xu, Jing Xu, Shimin Gong, Yi Wang
Machine Learning and Intelligent Communications, MLICOM 2019
A study on backscatter-aided hybrid data offloading for mobile edge computing, leveraging deep reinforcement learning to optimize the offloading strategy.